Redis底层中的数据结构
SDS
简单动态字符串(Simple Dynamic String),与C字符串不同。SDS结构体字典如下:
- buf 保存SDS的字符数据的字符数组
- len,已保存的字符串长度(字节数),结尾的’\0’字符不算在len中
- alloc, 预分配空间大小
- flags, SDS的头类型,控制SDS头大小
与C的区别:
- 常数复杂度获取字符串长度
- 自动分配内存,杜绝缓冲区溢出且减少分配内存次数
- 空间预分配
- 修改后的字符串长度len<1MB,会分配2*len+1byte的空间
- 修改后的字符串长度len>=1MB,会分配len+1MB+1byte的空间
- 惰性空间释放
- 进行字符串缩短操作后并不会马上释放空闲空间
- 空间预分配
- 二进制安全
- 无视’\0’等特殊字符串的影响,使得SDS可以保存任意二进制数据
IntSet
整型集合(Int Set),有序,长度可变。结构体字段如下:
- encoding 编码方式(16,32,64)
- length 元素个数
- contents 字节数组,保存集合数据
当新添加的元素大小超过现集合的编码类型表示的数值范围,IntSet会自动升级至合适的编码方式。过程:
- 扩容数组
- 倒序拷贝:将现有元素拷贝到正确的位置
- 添加新元素
IntSet不支持降级
Dict
字典(Dict),一种用于保存键值对的数据结构。由三部分组成:
- 哈希表
- 哈希节点
- 字典
哈希表dictht结构体字段:
- table 指向entry的指针
- size,哈希表大小,总是等于$2^n$
- sizemask,哈希表大小的掩码,总等于size-1
- used entry的个数
哈希节点dictEntry结构体字段:
- key 键
- v 值
- next 指向下一个entry的指针(解决哈希冲突)
字典结构体字段:
- type dict类型,内置不同hash函数
- privdata 私有数据,在做特殊hash运算时使用
- dictht ht[2] 一个字段包含两个哈希表,一个是当前数据,另一个为空,rehash时使用
- rehashidx rehash进度,-1表示未进行
- pauserehash rehash是否暂停,1则暂停
存取过程
对键值key调用哈希函数dict->type->hashFunction(key)得到哈希值hash,再通过hash & sizemask得到哈希表的索引位置。插入时若该索引上已有哈希节点,则用头插法把新键值插入链表上。
rehash
当哈希表保存的键值对数量太多时,必然导致哈希冲突增多,链表过长,查询效率降低,因此需要rehash进行dict扩容。扩容后必须对哈希表的每个key重新计算索引,插入新哈希表,这个过程就是rehash。
哈希表扩容条件与负载因子(LoadFactor = used / size)有关:
- LoadFactor >= 1, 并且服务器没有执行BGSAVE或BGREWRITEAOF等后台进程
- LoadFactor > 5
类似的,当LoadFactor<0.1时,就会触发哈希表收缩。
rehash过程:
- 计算新哈希表的size
- 申请新的dictht, 赋值给dict.ht[1]
- dict.rehashidx=0,表示开始rehash
- 将dict.ht[0]的每个entry进行rehash,保存到dict.ht[1]
- 将dict.ht[1]赋值到dict.ht[0],dict.ht[1]初始化为空哈希表,释放原来的dict.ht[0]内存
- redis中解决哈希冲突使用的是链地址法
- 因为哈希表大小size总是$2^n$,所以 hash & sizemask == hash % size
- BGSAVE或BGREWRITEAOF执行时,Redis会fork子进程,由因为linux等操作系统采用写时复制(copy on write),所以将扩容所需的LoadFactor提高,避免不必要的内存写入操作,最大限度节约内存
- rehash是分多次渐进式完成的:rehashidx设为0后,每次对字典执行增删改查式,就会将ht[0]韩信表在rehashidx索引上的所有键值对rehash到ht[1],并且rehashidx++;删改查等操作会在两个哈希表依次进行,新增操作直接在ht[1]上执行。
ZipList
压缩链表(Zip List),与双端链表类似,但不是通过指针连接,是实现列表键和哈希键的基础。结构体字段如下:
- zlbytes 结构体总字节数
- zltail 尾偏移量,为链表尾节点距离压缩链表启示地址的字节数
- zllen entry 节点个数,最大值为UINT16_MAX
- entryX,列表节点,长度不定
- zlend 为定值0xFF,用于表级列表末端
Entry字段:
- previous_entry_length:前一节点长度len
- 如果len < 254, 该字段只占1字节
- 如果len >= 254, 该字段占5字节,第一字节为0xFE, 后四个字节才是正事长度数据
- encoding:编码属性,记录content的数据类型以及长度
- 最高位以‘00’ ‘01‘ ’10’开头表明contents为字符串/字符数组;‘00’时encoding只占1字节,剩余位数表示contents字节长度;‘01’时encoding只占两字节,剩余位数表示contents字节长度; ‘10’时encoding占5字节,其中后四字节才表示contents字节长度
- 最高位以‘11‘开头表明contents为整数,encoding只占1字节,剩余位数表示不同的整数类型。值得注意的是,若encoding为’1111xxxx’,则该entry没有contents, 值为xxxx
- contents: 保存节点数据,可以是字符串或整数
连锁更新问题
连锁更新问题是压缩链表中发生概率较低的一种问题。假设当前链表所有entry字节长度都是250~253字节,某一时刻在链表头部插入一个长度超过253的entry,导致原来所有的entry的prevous_entry_length所占空间由1字节转化为5字节,发生频繁的内存扩容申请导致性能损耗较高。
ZipList虽然节省空间,但由于内存必须是连续空间,占用内存过多时申请内存效率很低。
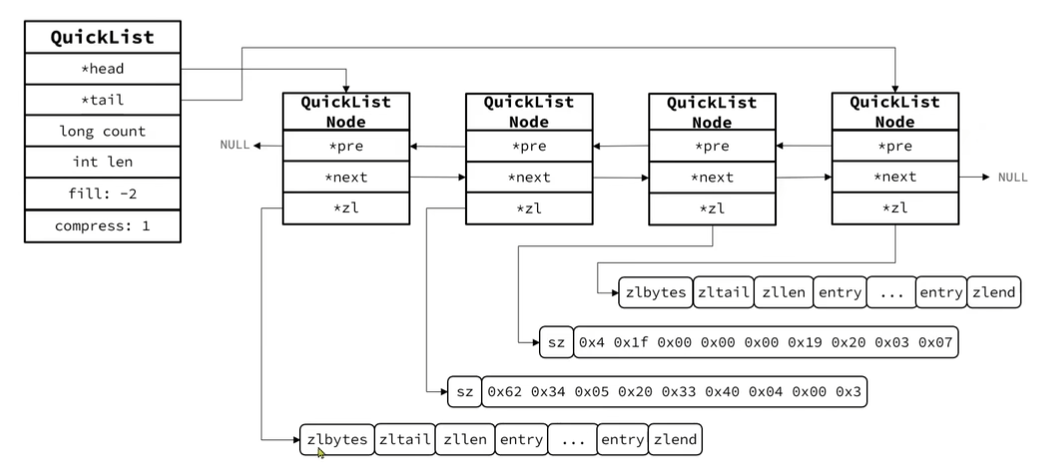
QuickList
是一个双端链表,但链表中每个节点都是一个ZipList
Redis提供了一些配置项:
list-max-ziplist-size来限制QuickList中每个ZipList的节点数量过多list-compress-depth来控制对节点的压缩深度;0时代表所有节点不压缩,1时表示首尾各一个节点不压缩;
SkipList
跳表(Skip List),是一种链表,是有序集合的底层实现之一,有以下特点:
- 元素按升序排列存储
- 节点可以包含多个指针,指针跨度不同
跳表结构体字段如下:
- header 跳表头节点
- tail 跳表尾节点
- level 跳表内最大的层数(不考虑表头节点的层数)
- length
跳表节点结构体字段如下:
- level[]
- forward 前进指针
- span 指针跨度,记录两节点的距离
- backward 后退指针
- score 分值
- obj redis对象
查询过程:
- 从最高层开始:查询操作总是从跳表的最高层开始,因为这一层的节点数量最少,可以最快地跨越较大的距离。
- 向前移动:在当前层级,比较目标值与当前节点的值。如果目标值小于当前节点的值,则向后退一步(如果可能的话),移动到当前节点的前一个节点;如果目标值大于当前节点的值,则尝试向右移动到下一个节点。
- 向下移动:如果当前层级已经没有更多的节点可以向右移动,那么就向下移动到下一层的相同位置继续查找。
- 重复步骤:重复上述步骤,直到找到匹配的目标值或达到最低层且无法再向右移动为止。
- 每个节点的层高是1至32的随机数
RedisObject
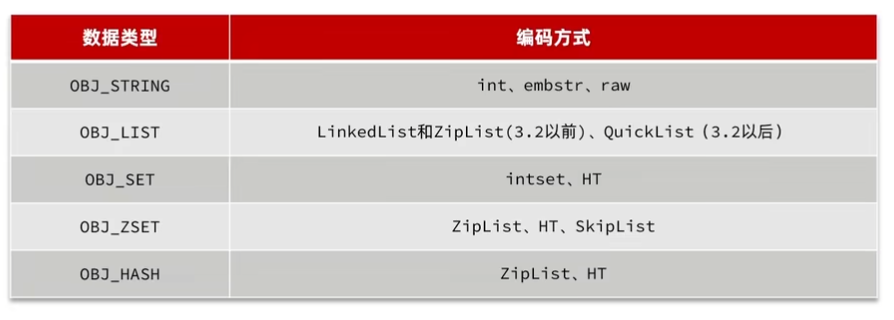
Redis中任意数据类型都会封装为一个RedisObject,结构体字段如下:
- unsigned type,记录对象类型
- REDIS_STRING
- REDIS_LIST
- REDIS_HASH
- REDIS_SET
- REDIS_ZSET
- usigned encoding,记录对象所使用的编码(底层数据结构),包括上述的数据结构
- void *ptr 指向底层实现数据结构的指针
- int refcount 记录对象的计数信息,用于内存回收和对象共享
- usigned lru 记录对象最后一次被命令查询访问的时间,可用于内存回收
可以使用TYPE命令查看一个键对应的值对象类型,OBJECT ENCODING查看底层使用的编码方式
- Redis执行命令前会检查给定键的类型能否执行指定命令,并检查编码来觉得执行命令的方法/函数
- Redis共享0到9999的字符串对象
 微信
微信 支付宝
支付宝